- BSP
- SynDEX
- Boîte à outils Max+
- Interpréteur Forth
- Principe moindre action
![]()
![]()
Table des matières:
 Références à Forth.
Références à Forth.- Histoire du Forth.
- Coloration syntaxique.
- Rapide aperçu de la théorie des langages.
- Forth un langage sans syntaxe.
- Forth un langage à piles.
- Dictionnaire Forth: une machine virtuelle.
- Différentes classes de mots.
- Fonctionnement de interpréteur externe.
- Fonctionnement de interpréteur interne.
- Variables et constante.
- Un langage evolutif.
Les documents (PDF, codes sources, programmes, ...) fournis sur ce site sont mis à disposition sous licences
 |  | |
|
|
| |
Page auto-générée le :
Le langage Forth
 Références à Forth
Références à Forth
Le but de ce document est de faire découvrir (ou redécouvrir) le langage Forth créé par Charles Moore, d'expliquer son fonctionnement interne et de mieux faire comprendre certains mots dits de hauts niveaux. Ce document montre aussi qu'il existe, non pas un unique langage Forth standardisé mais des Forth personnalisés et adaptés à chaque projet. Avant de poursuivre la lecture de ce tutoriel, voici une sélection non exaustive d'ouvrages et de liens que je recommande de lire. Je suggère aux lecteurs qui n'ont jamais connu ce langage de s'initier avec les quatre premiers liens puis, si possible le livre de W.P. Salman, O. Tisserand, B. Toulout qui est, selon moi, un livre de référence expliquant complétement le fonctionnement interne du Forth.
 Un
cours
Un
cours  académique sur le Forth. Ce document est intéressant car il parle de
la dernière variante de Forth inventé par Moore: colorForth.
académique sur le Forth. Ce document est intéressant car il parle de
la dernière variante de Forth inventé par Moore: colorForth. Starting Forth est le
cours d'introduction pédagogique recommandé pour s'initier à ce langage.
Starting Forth est le
cours d'introduction pédagogique recommandé pour s'initier à ce langage.-
Forth
W.P. Salman, O. Tisserand, B. Toulout. Edition Macmillan (english version) ou
Edition Eyrolles (french version) 1983. (ISBN-13: 978-0387912561, ISBN-10:
0387912568) est un excellent livre décrivant de façon complète la théorie du
fonctionnement d'un interpréteur Forth. Avec ce seul livre, il est possible de
re-créer son propre Forth. A noter que la version française 1983 contient
quelques erreurs de typographie dans du code Forth corrigées dans la version
anglaise (et probablement la version française de 1984).
- JonesForth
Un excellent tutoriel sur l'implémentation d'un interpréteur Forth écrit en
assembleur i386. Ce document en 2 fichiers (assembleur et forth) complète le
livre de W.P. Salman pour la clarté de ses explications et de son
implémentation très claire en code assembleur.
- CoreForth Il existe
beaucoup d'adaptation de JonesForth pour d'autre assembleur. Voici un
fonctionnant pour Arduino Due que j'ai pu tester: Un Forth pour Cortex M0 et
M3. Fonctionne chez moi avec une carte
Arduino Due .
- Object
Oriented Forth Livre expliquant comment faire évoluer son Forth pour le
programmer façon objet. Mon deuxième livre coup de coeur concernant Forth.
- Le Concept Forth de Pascal Courtois (français, ISBN-10: 2866990110, ISBN-13:
978-2866990114). Explique les mots de base, comment fonctionne un interpréteur
Forth mais est moins complet que le livre Forth de W.P. Salman. On peut
trouver des extraits sur le site de developpez.net (avec l'aimable
autorisation de son auteur). Il donne des programmes assembleur sur des
interpréteurs Forth mais ils sont difficilement compréhensibles et pour des
vieux micro et il vaudra mieux se baser le lien précédent.
- Entrer dans le monde du Forth Très
belle réalisation de cartes électroniques pour systèmes Forth. Les
explications sont claires mais peu nombreuses.
- Thinking Forth Livre
pour les développeurs modérés en Forth donnant des conseils sur comment bien
penser son projet en Forth. Ce livre est destiné pour les enthousiastes non
débutants.
- forth2012 le
glossaire Forth ANSI 2012.
Voici une liste non exhaustive de Forth non payants :
- gForth le Forth GNU
toujours activement développé et servant de référence.
- 4th
un Forth considéré comme ne crashant jamais.
- pForth un Forth connu
à son époque et portable en C mais n'est plus développé.
- reForth un
Forth écrit en C avec des modifications intéressantes vis à vis des
Forth standards. Il n'est plus développé.
- SimForth
 mon interpréteur Forth fait
maison écrit en C++ pour les besoins de mon projet personnel de cartes
géographiques SimTaDyn. Il est inspiré de pForth et du livre
et créé contenant son mon interpréteur Forth. J'utilise l'héritage du C++ pour
avoir à la fois un interpréteur Forth classique (compilable séparément du
projet principal), tout en ayant un interpréteur spécialisé pour mes cartes
géographiques.
mon interpréteur Forth fait
maison écrit en C++ pour les besoins de mon projet personnel de cartes
géographiques SimTaDyn. Il est inspiré de pForth et du livre
et créé contenant son mon interpréteur Forth. J'utilise l'héritage du C++ pour
avoir à la fois un interpréteur Forth classique (compilable séparément du
projet principal), tout en ayant un interpréteur spécialisé pour mes cartes
géographiques. - FreeForth un
Forth fait par le regretté Christophe Lavarenne, où le mode exécution n'existe
plus et est remplacé par la compilation d'un mot anonyme.
Histoire du Forth
Forth est un langage inventé par Charles H. Moore dans les années 1970 afin de palier la lourdeur des langages de l'époque incompatibles pour des applications temps réel, Moore travaillant à l'époque à l'Observatoire National de Radio-Astronomie des Etats-Unis. Forth a été conçu pour être le plus simple et minimaliste possible où avec environ 150 mots du langage, un petit système d'exploitation peut être créé. Forth fut, par la suite, devenu un langage largement utilisé dans ce milieu (comme par la NASA) mais aussi pour des machines personnelles telles que le Machintosh avec le MacForth (pour ne citer que lui). Forth a été utilisé, à ces époques, en industrie pour tester et déboguer les registres des nouveaux chips (SoC). Actuellement, le prix du stockage mémoire ayant fortement baissé et la puissance brute en calcul augmentée, l'optimisation des ressources des systèmes embarqués est devenu moins critique, ce langage est devenu beaucoup moins à la mode là où le C demeure toujours en maître.
Comme nous allons le détailler tout le long de ce document, faire son propre
interpréteur Forth est relativement aisé, chacun pouvant implémenter le sien
mais pas forcément compatible avec celui d'un autre. Cela fut un point noir
de ce langage, qui malgré plusieurs tentatives de standards (78, 79, 83,
2012 ...) pour normaliser les mots les plus courants, ne furent pas forcément
bénéfique au langage: Charles H. Moore est toujours actif mais il a quitté le
consortium, jugeant que la normalisation nuisait à l'innovation de nouveaux
Forth. Il a ainsi pu continuer à simplifier les structures Forth comme
expliqué dans
le lien
suivant, section Structures simplifiées ![]() . Avec
colorForth
. Avec
colorForth ![]() Moore a ajouté un rôle aux mots en leur ajoutant une
couleur
Moore a ajouté un rôle aux mots en leur ajoutant une
couleur ![]() . Pour plus
d'information confère ce
document
. Pour plus
d'information confère ce
document ![]() . Moore a
également fondé GreenArrays Inc. qui produit des puces
GA144
. Moore a
également fondé GreenArrays Inc. qui produit des puces
GA144 ![]() contenant un réseau communicant de sous-processeurs Forth dont le
brevet
contenant un réseau communicant de sous-processeurs Forth dont le
brevet ![]() explique clairement
le fonctionnement (et est très lisible pour un brevet).
explique clairement
le fonctionnement (et est très lisible pour un brevet).
Nous allons, tout au long de ce document, revenir sur chaque éléments de la définition, mais en quelques mots Forth peut-être résumé à :
- un langage à piles;
- un langage extensible avec une syntaxe auto-évolutive (ré-entrance, métaprogrammtion);
- semi-compilé (embarquant son propre compilateur hybridé avec un interpréteur);
- peut être vu comme un système d'exploitation car il est à la fois un langage, une machine virtuelle car Forth sait gérer sa propre mémoire de masse et dispose d'entrées/sorties;
- il est à la fois un langage bas-niveau (manipulant de l'assembleur et des registres hardware) et un langage haut-niveau (abstraction des données, faible couplage, peut être orienté objet, etc);
- bien que la plupart des langages soient complets au sens de Turing, Forth offre à l'utilisateur la possibilité d'accéder directement aux différents éléments d'une machine de Turing (ruban infini, tête de lecture/écriture, registre d'état, table d'actions.)
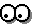 Coloration syntaxique
Coloration syntaxique
Pour ce document, nous allons, concernant la coloration syntaxique, prendre une convention qui n'est pas officielle mais inspirée de colorForth, mais dans ce document la couleur est purement décorative, contrairement à colorForth qui ajoute une information aux mots Forth pour le compilateur:
| Couleur: | Mode de l'interpréteur: | Commentaire: |
| En gras | ignoré | Les commentaires |
| En gris | compilation/exécution | les mots manipulant les nombres dans la pile des données |
| En rouge | compilation | la définition d'un nouveau mot |
| En orange | compilation | les mots immédiats |
| En bleu | exécution | les littéraux |
| En vert | exécution | saute sur la définition d'un mot non primitif |
- En rouge les littéraux;
- En vert la définition d'un nouveau mot;
- les mots immédiats;
- En bleu les mots de structure conditionnelle;
- En gris les commentaires.
Rapide aperçu de la théorie des langages
Le but de cette section n'est pas d'expliquer la théorie des langages mais plutôt de faire resentir au lecteur la difficulté de ce sujet et par contraste de montrer la simplicité du langage Forth. Par conséquent, cette section empruntera de grossiers racourcis.
Pour rappel et faire très simple, en théorie des langages, un compilateur est un outil qui transforme un langage informatique en un autre langage. Par exemple du langage C au langage machine directement exécutable. Pour cela un compilateur utilise généralement deux outils:
- Un lexer est un outil d'analyse lexicale qui convertit un texte (entrée) en une liste d'unité lexicale (sortie) appelée symboles (tokens en anglais).
- Cette liste est ensuite consommée par un second outil appelé parser
qui retourne un
arbre de syntaxe
abstraite (AST en anglais) où les noeuds de cet arbre sont les opérateurs et
les feuilles les opérandes et que l'on visite avec un parcours
main-gauche . Le
terme abstrait vient du fait qu'un
Parse tree est une
représentation concrète et complète du texte alors que l'AST ne garde que
certains de ces éléments.
Une fois l'AST construit, cette structure est plus simple pour le compilateur de la travailler. Un compilateur C aurait analyser un certain nombre fois une analyse de l'AST pour créer des AST intermédiaires contenant des pseudo-instructions de plus en plus proche des instructions assembleur de la machine cible. Il aurait également généré un graphe colorié afin de connaître le nombre minimal de registres nécessaires pour stocker les variables locales (par exemple dans notre cas, un registre pour stocker le résultat 14), etc.
Donnons un exemple de code en langage C:
display(2 + 3 * 4);
Un compilateur C, lors d'une première passe d'interprétation, aurait détecté la priorité de la multiplication sur l'addition via une grammaire non-ambigue et aurait ajouté implicitement les parenthèses suivantes:
display(2 + (3 * 4));
puis aurait généré un ParsTree similaire à:
expr
|
------------------
| | |
display factor term
| |
----------- ;
| | |
( expr )
|
---------------
| | |
term + factor
| |
2 ------------
| | |
( expr )
|
-------------
| | |
term * term
| |
3 4
Puis un AST:
display
/
+
/ \
* 2
/ \
3 4
Puis des AST avec des instructions de plus en plus proches du langage machine et obtenir du code similaire à ça. Ici on ne montre pas le graphe coloré pour allouer le moins de registres possibles:
push %eax ; save value of e1 on the stack
pop %ecx ; pop e1 from the stack into ecx
addl %ecx, %eax ; add e1 to e2, save results in eax
...
En langage LISP, grâce à sa syntaxe représentant des arbres, on aurait implicitement l'AST car on aurait écrit quelque chose d'approchant à :
(display (+ (* 3 4) 2))
En Forth, qui est un langage utilisant la notation polonaise inversée, on aurait écrit :
3 4 * 2 + display
L'interpréteur Forth se contente simplement d'extraire les mots séparés par des espaces.
Forth un langage sans syntaxe
Forth est à la fois un interpréteur et un compilateur. Forth ne compile pas le code en langage machine (comme pour le langage C) mais du byte-code dans une machine virtuelle (comme pour Java).
Forth, contrairement aux langages tels que le C ou Python, n'a pas de grammaire ambiguë, ne nécessite pas de rétro-action lexicale, etc. Un script Forth est une simple suite de symboles séparés par des espaces. Il n'y a donc aucune syntaxe. Par conséquent un compilateur Forth est un simple lexer sans son parser. Quand Forth va lire un script, il n'a besoin que d'extraire et de reconnaître le symbole courant (qui doit être soit un symbole qui lui est "connu", soit un nombre) et parfois le symbole suivant quand celui-ci n'est pas encore connu (comme par exemple lors de la définition d'un nouveau symbole/définition Forth). Dans une section de ce document, on expliquera ce que le verbe "connaître" signifie concrètement. Nous verrons également que ce sont les symboles eux mêmes qui agissent directement sur le comportement du compilateur et non le compilateur qui s'adapte aux mots rencontrés.
Dans la convention Forth, une unité lexicale est appelé mot (word en anglais) et sa signification est proche de celle du langage naturel humain. Egalement par convention, un mot Forth est formé de n'importe quelle suite de caractères ASCII (il n'y a réellement aucune restriction contrairement à des langages tels que C) dont, historiquement, la taille maximale est 32 caractères ASCII (mais cette limitation a disparue sur les Forth modernes tels que gForth). Certains Forth sont sensible à la case (sensible aux minuscules et majuscules) d'autres non. Au début Forth écrivait les mots en majuscules. Dans ce document on utilisera cette convention.
Cette absence de syntaxe s'explique facilement: Forth utilise la wnotation polonaise inversée (Reverse Polish notation) à savoir que les opérandes (paramètres) sont notées avant les opérateurs. Cette notation évite l'utilisation de parenthèses palliant l'ordre de priorité des opérateurs (par exemple en mathématique la priorité de la multiplication sur celle de l'addition) et évitant ainsi l'utilisation d'une grammaire complexe impliquant la création d'un AST.
Le code Forth suivant :
2 3 4 + *
équivaut à l'expression arithmétique 2 * (3 + 4) alors que le code Forth suivant :
2 3 4 * +
équivaut à l'expression arithmétique 2 + (3 * 4).
Si l'on désire afficher à l'écran le résultat de l'opération on utilisera le mot Forth . qui affichera l'entier valant 14. Note: en Forth, le mot DISPLAY n'existe pas, son nom exact est . (dot en anglais).
2 3 4 * + .
Le travail de l'interpréteur Forth est assez trivial: il se contente d'extraire les symboles à la volée (simplement de gauche à droite), il empile les nombres qu'il rencontre et exécute les opérandes (les mots Forth) consommant une certaine quantité de données dans cette pile puis, si résultat il y a, empilera le résultat. La section suivante expliquera mieux ce processus.
Mode compilation et mode interprétation: Si l'on désire créer un nouveau mot Forth, on utilisera le mot Forth : suivi du nom du nouveau mot Forth à définir, puis d'une suite de mots Forths connus ou de nombres et finalement du mot ; qui termine la définition. Les mots : et ; sont des mots primitifs du langage, à savoir des mots exécutant du code machine. Par exemple:
: MON-CALCUL 2 3 4 * + ; est l'équivalent du code C:
int mon_calcul() { return 2 + 3 * 4 ; }
S.push(mon_calcul());
J'ai fait correspondre les couleurs. Par exemple : du Forth correspond au () { } du C. On remarquera qu'en Forth que contrairement au langage C le points virgules sont inutiles et ne servent pas à séparer les instructions entre elles. Une convention Forth suggère de séparés les phrases Forth par trois espaces. En colorForth, le point virgule sert de return.
Chaque fois que MON-CALCUL sera extrait du flux d'entrée par le parseur, de l'interpréteur Forth, ce dernier calculera et retournera le nombre 14. Il est clair que MON-CALCUL est devenu un mot Forth connu mais revenons en arrière avec l'extrait de code : MON-CALCUL car on peut se poser la question: est ce que l'interpréteur échouera quand il tentera d'exécuter le mot MON-CALCUL qui lui est inconnu ? C'est exact mais c'est l'exécution du mot : qui va commuter l'interpréteur en mode compilation et lui indiquer que le mot suivant (à savoir MON-CALCUL) doit être ajouté dans l'index de recherche des mots connus. En mode compilation tous les mots connus sont compilés en byte code. Un mot inconnu est considéré purement et simplement comme un erreur. On pourrait croire que le mot ; sera lui aussi compilé mais ce n'est pas le cas. En effet ce mot est un mot de haut niveau qui, quand il est exécuté, et ce même quand le compilateur est en mode compilation, fait repasser l'interpréteur en mode interprétation. Nous analyserons plus en détail ce fonctionnement exact dans la section traitant des mots Forth de hauts niveaux.
Mots primitifs et mots secondaires: il est important que rappeler que les mots bleus tels que + sont des primitives du langage à savoir appelant du code machine alors que les mots rouges tels que MON-CALCUL sont des mots secondaires (secondary words) définis par l'utilisateur et qui appelent d'autres mots Forth (primitifs et ou secondaires).
Le mot MON-CALCUL a été compilé en byte-code et désormais il est maintenant un mot connu de l'interpréteur. Nous y reviendrons dans une section future. Nous pouvons imbriquer ce mot dans une nouvelle définition. Forth est un Langage tissé. Par exemple:
: PRINT-CALCUL MON-CALCUL . ; Quand on exécutera PRINT-CALCUL le nombre 14 sera affiché. En effet: PRINT-CALCUL appelera MON-CALCUL qui retournera 14, nombre qui sera consommé et affiché par le mot . est l'équivalent du code C:
int mon_calcul() { return 2 + 3 * 4 ; }
void print_calcul() { display(mon_calcul()) ; }
print_calcul();
Gestion des commentaires: Il existe plusieurs format de commentaires en Forth. Le mot \ ignore la ligne complète. Par exemple:
: MON-CALCUL \ Fait un calcul
2 3 4 * + ; ignorera Fait un calcul. Attention \ est un mort Forth: il exécute du code: celui d'ignorer tous les caractères jusqu'à rencontrer le retour chariot. En conséquence, il faudra placer au moins un espace pour que l'interpréteur puisse le séparer des autres tokens. Par exemple:
: MON-CALCUL \Fait un calcul
2 3 4 * + ; Produira une erreur indiquant que le mot \Fait est inconnu de l'interpréteur. L'autre type de commentaire sont les parenthèses. Par exemple:
: MON-CALCUL ( Fait un calcul)
2 3 4 * + ; Tout comme le mot \, le mot ( est un mot Forth. il lui faut un espace pour être reconnu. Ce mot ignore tous les caractères jusqu'à rencontrer le premier caractère ) qui lui, pour le coup, n'est pas un mot Forth et n'a donc pas besoin d'être espacé.
Le lecteur trouvera tout cela très compliqué comme règles ? Malgré le peu de vocabulaire Forth présenté jusqu'à présent dans ce document. Le lecteur changera probablement d'avis quand il constatera la facilité de construire son propre système de commentaire :
: ( 41 WORD DROP ; IMMEDIATE Explications: 41 est le code ASCII de ) qui sera placé sur
le sommet de la pile de données. Le mot WORD le consommera et ignorera
tous les caractères du flux de caractères jusqu'à rencontrer le bon code
ASCII. WORD retourne la position du flux, information inutile et donc
éliminée par le mot DROP. Finalement le mot IMMEDIAT (qui sera
expliqué plus longuement dans une section suivante) rend ce mot exécutable
lors de la compilation d'un mot. Par exemple, dans l'exemple précédant
concernant MON-CALCUL, il aurait été gênant de compiler le commentaire
Fait un calcul en byte code. Pour la définition du mot \ on
remplacera le code ASCII de ) par le code ASCII du retour chariot. Le lecteur
attentif aura remarqué que les commentaires Forth, avec cette définition
issue du standard, ne permet pas de nicher des sous commentaires. JonesForth propose une
solution ![]() .
.
En conclusion pour cette section, nous venons de voir comment avec un langage sans syntaxe nous avons facilement pu implémenté un début de syntaxe. Nous verrons plus tard que les mots de liaisons tels que le IF THEN ELSE, boucles seront tout aussi facilement implémentées.
 Forth un langage à piles
Forth un langage à piles
En informatique une
pile ![]() (stack en
anglais) est une structure pour stocker des éléments et par analogie avec la
pile d'assiettes, c'est la dernière assiette (dernière donnée) déposée qu'on
ira prélever en premier. Une pile est également nommée LIFO pour Last In
First Out. Des langages, tels que le C, cachent délibérément au développeur
l'utilisation d'une pile de contexte pour sauvegarder des informations. Par
exemple, lorsque une fonction appelle une autre fonction, le compilateur va
empiler:
(stack en
anglais) est une structure pour stocker des éléments et par analogie avec la
pile d'assiettes, c'est la dernière assiette (dernière donnée) déposée qu'on
ira prélever en premier. Une pile est également nommée LIFO pour Last In
First Out. Des langages, tels que le C, cachent délibérément au développeur
l'utilisation d'une pile de contexte pour sauvegarder des informations. Par
exemple, lorsque une fonction appelle une autre fonction, le compilateur va
empiler:
- les paramètres passés à la fonction,
- les variables locales de la fonction,
- et bien d'autres information comme le code de retour de la fonction
- le pointeur d'interprétation ...
Ceci peut parfois entraîner des pénalités en temps d'exécution du programme (passage de trop de paramètres, passage des paramètres volumineux par copie au lieu de leur adresse), voir des crashs par débordement de la pile d'appels (stack overflow) ce qui peut arriver, par exemple, dans les cas suivants:
- soit en passant par copie des données trop grosses,
- soit en utilisant la récursivité sur des langages mal adaptés à la récursion terminale tels que le C ou Forth. Pour information OCaml est un langage maîtrisant nativement la récursion ainsi que colorForth.
Le lecteur notera, dans le titre, l'utilisation du pluriel pour le mot pile car nous allons voir que Forth utilise deux piles:
- une première pile accessible au développeur nommée Data Stack ou bien Parameter Stack ou bien S. Elle sert à stocker les données qui sont les paramètres des mots Forth (équivalents des fonctions en C);
- une seconde pile nommée Return Stack ou bien R, utilisée par l'interpréteur pour sauvegarder l'ordre des appels des mots. Nous verrons qu'elle est en fait partiellement accessible au développeur.
Pile de données: En Forth, avec la notation polonaise inversée, les opérandes sont directement stockés dans une pile de données et les opérateurs (les mot Forths) les consomment. Par conséquent, contrairement à des langages comme le C, la pile évite à Forth l'utilisation de variables temporaires nommées (équivalent aux variables locales du C). Ceci est à la fois un avantage et une faiblesse du langage: le programmeur Forth doit organiser l'ordre des éléments dans la pile avant leur consommation (avec des mots tels que DUP, SWAP, OVER) ce qui ajoute de la pollution à la lecture du code source. Certains Forth non-standards reprennent cette idée de variables locales nommées: une partie de la pile est transférée vers ces variables pour une utilisation directe et ainsi simplifié le code source.
Supposons la pile S initialement vide puis exécutons le code suivant:
2 DUP + . - L'interpréteur va placer l'opérande 2 dans la pile (qui aura donc son premier élément).
- Le mot DUP va le consommer (dépiler) puis le dupliquer (DUPlicate en anglais). La pile aura deux éléments.
- Le mot + consommera les deux éléments de la pile (deux dépilements)
- les additionnera et empilera le résultat (soit la valeur 4).
- Finalement le mot . va dépiler la valeur et affichera sa valeur à l'écran (équivalent du stdout du C). La pile de données se retrouve dans son état d'origine (vide).
Il est de la responsabilité du développeur de vérifier qu'il y ait toujours le bon nombre d'éléments dans la pile. Si un mot veut consommer des éléments non présents dans la pile, certains interpréteurs vont interrompre tout le programme et le signaler à l'utilisateur par un message d'erreur de type "stack underflow", d'autres interpréteurs ne testeront même pas l'erreur pour des soucis de rapidité. En colorForth la pile est une simple pile circulaire pouvant contenir jusqu'à 8 éléments. En gforth la taille de la pile peut être définie par l'utilisateur est peut contenir par défaut des milliers d'élements.
Pile de retour: cette pile est utilisée pour mémoriser l'ordre des
appels des mots Forth appelant d'autres mots Forth (secondary words)
tels que MON-CALCUL et PRINT-CALCUL (pour rappel le mot DUP
est une primitive du langage à savoir appelant du code machine). Pour bien
comprendre la raison de son existence, rappelons nous des algorithmes de
parcours d'arbre. Sur la figure suivante, nous souhaitons simuler un repas en
parcourant les noeuds de cet arbre avec un parcours préfixe main gauche
main-gauche ![]() .
.
Cliquez pour agrandir l'image.
Avant d'expliquer l'algorithme, voyons d'abord le résultat attendu d'un parcours préfixe: repas, entrée, déjeuner, poulet, frites, désert. Les mots repas, déjeuner, qui sont les noeuds, n'ont pas de signification intéressante, pour cela on ne gardera que les feuilles de l'arbre (feuille est noeud ayant aucun fils), on obtient alors: entrée, poulet, frites, désert. Pour obtenir ce résultat, on peut penser à deux algorithmes: -- l'un récursif, -- l'autre itératif.
Voyons d'abord la version récursive de l'algorithme d'un parcours préfixe main gauche. Pour simplifier on supposera que l'arbre binaire (à savoir soit au max deux sous-arbres par noeud), en effet, pour un arbre général (comme sur la figure précédente), on remplacera fils gauche/droit par le N-ième fils:
explorer(arbre A):
afficher le noeud de A;
si A a un fils gauche alors explorer(fils gauche de A) fin si;
si A a un fils droit alors explorer(fils droit de A) fin si;
Cet algorithme utilise implicitement une pile pour sauvegarder les noeuds parcourus. Le compilateur va gérer automatiquement la pile d'appel pour nous (Rappelez vous quand je disais que le langage C cachait au développeur l'utilisation de cette pile). Maintenant, voyons comment est gérée cette pile, en utilisant un algorithme itératif:
explorer(arbre A):
créer une pile vide;
empiler(A);
tant que la pile n'est pas vide faire:
noeud <- dépiler;
afficher noeud;
si noeud a un fils gauche alors empiler(son fils gauche) fin si;
si noeud a un fils droit alors empiler(son fils droit) fin si;
fin tant que
Quel est le lien avec Forth ? L'interpréteur Forth dès qu'il lit un nouveau symbole sur son entrée (par exemple MON-CALCUL) va l'interpréter de façon similaire à notre algorithme d'exploration d'arbre à la différence près qu'il ne se contentera pas d'afficher le noeud mais exécutera les instructions machine des mots Forth primitives (tels que DUP). La pile utilisée dans le pseudo-code est cette fameuse pile de retour R que l'on a introduit précédemment.
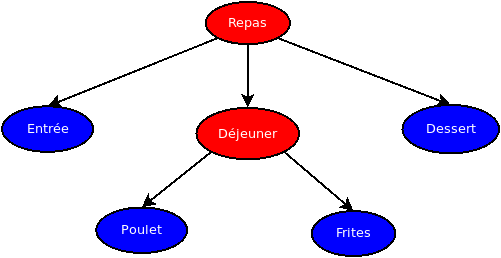
On peut se poser une autre question: quel est le lien entre un mot Forth est un arbre ? Un mot Forth connu de l'interpréteur à implicitement une structure d'arbre. Supposons que notre Forth connaisse les mots primitifs suivants: ENTREE, POULET, FRITES, DESERT. Nous pouvons créer les mots suivants:
: DEJEUNER POULET FRITES ;
: REPAS ENTREE DEJEUNER DESERT ;
L'arbre général qui était REPAS est devenu un arbre binaire dans Forth et les noeuds qui avaient la même hauteur sont maintenant liés entre eux.
Cliquez pour agrandir l'image.
Attention, en interne, une structure classique d'arbre (avec noeud et deux pointeurs) n'est pas utilisée. Les pointeurs ne sont rien d'autre que le byte-code (identifiant des mots compilés). Cela sera plus clair pour le lecteur lorsque nous aborderons le chapitre sur le dictionnaire car nous n'avons pas encore abordé comment les mots Forth sont représentés en mémoire (section suivante). Pour le moment le lecteur doit accepter le fait que les fils gauches sont une adresse vers l'emplacement mémoire d'un autre mot Forth et que les fils droits n'existent pas, ils sont implicites car les noeuds sont placés consécutivement dans la mémoire (par exemple le byte code des mots ENTREE, DEJEUNER et DESSERT sont consécutifs en mémoire dans la définition du mot REPAS).
Maintenant, avec cet arbre binaire, si l'on exécute uniquement les noeuds qui n'ont pas de fils gauche, on obtiendra le résultat attendu: ENTREE, POULET, FRITES, DESERT qui sont uniquement des mots primitifs. On comprendra mieux par la suite comment est implémenté le parcours d'arbre des mots en Forth.
La pile de retour un pile semi-privée ? Les débutants peuvent ignorer ce paragraphe dans un premier temps! La pile de retour n'est pas une pile privée totalement privée. Elle est en fait partiellement accessible au développeur mais cela peut présenter un énorme risque de crash du programme. En effet cette pile de retour peut être aussi utilisée comme pile de stockage temporaire de la pile de données avec des mots >R et R>. Cette pile est utilisé en même temps à la fois par l'interpréteur et le développeur. C'est le cas par exemple pour les mots implémentants les boucles : les compteurs sont parfois déplacés sur cette pile. Il faudra faire attention à laisser cette pile propre (pour cela il faut que le nombre mot >R et R> soient balancés) sous peine de faire crasher l'interpréteur en exécutant une valeur de la pile de données en le prenant pour un byte-code à exécuter. Pour rappel, Forth a été conçu dans les années 70 où le moindre octet était peu nombreux et coûteux et donc le moindre hack pour économiser de la mémoire était privilégié à la sécurité. Maintenant avec la puissance énorme des processeurs, il est plus simple de créer une deuxième pile de données.
Piles auxiliaires: Pour éviter les crashs avec les mots >R et R> certains Forth les ont interdit et rend privée l'accès à la pile de retour. En contre-partie, il est proposé à l'utilisateur une seconde pile de stockage des données. De plus, les Forth initiaux ne manipulent pas de nombres flottants nativements (la pile de données stocke uniquement des entiers 16 bits). Ces pile sont émulées en Forth et résident dans le dictionaire.
Notation des piles: Nous avons vu dans la section précédente que dés que le l'interpréteur exécutera le mot ( il ignorera tous les mots jusqu'à trouver le mot ). Ce type de commentaire est utilisé pour commenter les paramètres d'entrée et de sorties du mot et donc les piles. Il existe de nombreux documents sur internet qui en traite. Mais dans ce document nous allons beaucoup simplifié. Par exemple pour le mot NIP qui supprime le deuxième éléments au sommet de la pile:
: NIP ( a b -- b ) SWAP DROP ; Le commentaire indique que ce mot consomme deux nombres dans la pile de données: a et b (où a est le premier élément et b le second) et en produit un seul (b, le second paramètre) est équivalent au code suivant:
int nip(int a, int b) { return b; }
S.push(nip(S.pop(), S.pop());
Comment sont implémentées les piles ? Deux réponses possible selon le langage qui implémente l'interpréteur Forth:
- Assembleur: Forth étant un langage pour micro-contrôleur, les
mots primitifs du langage (à savoir les mots constituants le coeur du système)
pointent sur du code assembleur, une des piles utilise le registre de
la pile interne aux micro-contrôleur, l'autre pile doit être gérée
explicitement. Le noeud de notre arbre est le registre PC et il faut un
registre d'interprétation IP qui se déplace automatiquement et exécute les
instructions assembleurs des mots. L'existence des fils est géré par le mot
Forth spécial RETURN qui doit être collé aux mots primitifs. Je
conseille vivement de lire le tutoriel de
JonesForth
pour plus de renseignements. Il est très complet à ce sujet. j'ajouterai une
simple remarque: on voit que nos micro-contrôleurs modernes avec des
architectures RISC (ou équivalentes) sont des monstres en comparaison à un
micro-contrôleur dédié aux instructions Forth qui a besoin de 2 piles et de 2
registres.
- Langage de haut niveau: tel que le C, pour un soucis de portabilité les piles seront émulées par un tableau statique et les registres IP et PC seront émulés par un switch case sur les primitives et une variable.
Dictionnaire Forth: une machine virtuelle
Pour résumer ce qu'on l'a vu, Forth est un langage extensible (tissé): à partir de quelques mots de base on peut créer un nouveau mot plus évolué. Par exemple, le code suivant:
: SQUARE DUP * ;
Permet de définir un nouveau mot Forth SQUARE via les mots : et ; (qui jouent le rôle de début et de fin de définition). Une fois ce mot défini, il sera reconnu en tant que mot Forth valide par l'interpréteur. Dans notre cas, quand SQUARE sera exécuté, il calculera la puissance deux du nombre stocké dans la pile. Par exemple, le code suivant, consommera le nombre 5 posé de la pile et affichera le nombre 25.
5 SQUARE .
Nous avons également vu que l'exécution de mots Forth se rapproche d'un parcours d'arbre. Cette section fait enfin ce lien, en expliquant comment les mots Forth sont stockés en mémoire et se réfèrent entre eux.
Il n'y a pas une unique structure de dictionaire possible. La norme Forth laisse libre son implémentation. Pour ce document nous nous baserons sur la structure originelle (Forth 78): les mots Forth (entrées) et leur définition sont stockés dans une structure de donnée appelée par convention le dictionnaire (dictonary en anglais). Un mot Forth stocké dans ce dictionnaire sera reconnu par l'interpréteur et sa défiontion pourra être exécutée.
Le dictionnaire est un segment mémoire et peut être vu comme le ruban infini d'Alan Turing. Il est divisé en cases mémoire consécutives et par convention on les nomme cellule (cell en anglais). Une cellule stocke un token (byte code). Leur taille en octets dépend de l'architecture de la cible. Nous nous baserons pour ce document sur une architecture 16-bits, donc un mot sera codé sur deux octets. Par conséquent la taille d'un dictionnaire est 216-1 soit 64 Ko (ce qui est suffisant pour stocker un programme Forth). Pour rappel Forth étant né dans les années 70, il est très adapté aux micro-controlleurs 8 ou 16-bits et est moins bien adapté pour des architectures 32 ou 64-bits, à cause des alignements des adresses mémoires et du padding implicite. Pour ne pas compléxifier cette lecture nous ne attarderons pas au problème d'alignement.
Voici la structure mémoire d'un mot Forth:
<---------- Entête ---------->
- - - -----------+---------------+------+------------------------+-------+---- - - - - - - - - - - -
Fin mot précédent | Taille, flags | Nom | Pointeur mot précédent | Token | Définition | Début mot suivant
- - - -----------+---------------+------+------------------------+-------+---- - - - - - - - - - - -
^ ^ ^ ^
| | | |
NFA LFA CFA PFA
- Les informations Taille, Flags sont codées sur 1
seul octet.
- Taille: code sur les 5 bits de poids faible, le nombre de caractères ASCII du nom du mot Forth;
- Flags: code sur les 3 bits de poids fort les informations
suivantes:
- Smudge bit : indique si le mot doit être ignoré lors d'une recherche dans le dictionnaire. Ce drapeau est placé dans deux cas : -- soit l'utilisateur a décidé de supprimer le mot (avec le mot HIDE); -- soit d'une définition avortée (l'utilisateur a fait une erreur comme une typo sur un mot de la définition qui n'a donc pas aboutie).;
- immediat bit : si le mot doit être immédiatement interprété (exécuté) dés que l'interpréteur le lit et ce même si l'interpréteur est entrain de compiler un nouveau mot. Les seuls mot Forth immédiats que l'on connaît à ce niveau du document sont le mot ( pour les commentaires et le mot ; qui termine la définition d'un mot et accessoirement finalise le Smudge bit. S'il n'avait pas été immédiat l'interpréteur l'aurait ajouté dans la définition du mot en cours. Il faut pouvoir indiquer au compilateur quand s'arrêter.;
- et le dernier bit toujours à 1 servant de séparateur entre les entrées du dictionnaire (soit valant 80 en base 16). Il permet de retrouver le début de définition d'un mot et donc de pouvoir séparer plus facilement les mots entre eux.
- Nom est le nom du mot Forth et le nombre de caractère ASCII consécutifs est variable et est donné par l'information Taille:. Le nombre max de caractère est donc 25-1.
- Pointeur vers le mot précédent: LINK POINTER : est l'adresse de l'entrée précédente du dictionnaire. Les mots Forth sont stockés dans le dictionnaire comme une liste simplement chaînée et dont l'interpréteur maintient automatiquement la tête de la liste. L'interpréteur peut ainsi savoir si un mot existe. Les adresses peut être relatives ou absolues (la première ayant la bonne propriété de permettre de déplacer un bloc mémoire du dictionnaire sans devoir changer l'ensemble des adresses). Le nombre d'octets d'une adresse dépend de l'architecture choisie, ici 16 bits et par conséquent la taille d'un dictionnaire est 216-1 soit 64 Ko.
- Token ou XT en abrégé (execution token). Dépend de l'implémentation de l'interpréteur: certains Forth (comme le mien écrit en C) est un simple identifiant.
- Définition : est une suite de tokens chacun identifiant un mot déjà existant et compilé dans le dictionnaire, que l'on nommera par convention Code Field Address (CFA).
Certaines adresses sont importantes en Forth et possèdent un nom :
- NFA: Name Field Address pointe sur l'entrée d'un mot;
- LFA: Link Field Address pointe sur l'emplacement contenant l'adresse du mot défini précédemment. On rappelle qu'elle sert à parcourir les entrées du dictionnaire et savoir si un mot est connu de l'interpréteur. Les mots qui ont leur Smudge bit sont ignorés mais quand même traversés. Le dernier mot stocké (et donc le premier cherché) est référencé par le mot Forth LATEST;
- CFA: Code Field Address pointe sur le début de la définition d'un mot. Il ne faut pas le confondre avec LFA car il sert à déplacer le pointeur d'interprétation de l'interpréteur (pointeur sur le mot à interprété). Il faut le voir comme une sorte d'identifiant sur les mots sorte de bytecode d'une machine virtuelle java;
- PFA: Parameter Field Address pointe sur le second emplacement de la définition.
: CFA 2 - ; ( PFA -- CFA)
: LFA 2 - ; ( CFA -- LFA)
: NFA ( PFA -- NFA)
4 - ;
BEGIN
DUP
80 AND 0=
for
1 -
REPEAT
;
La primitive ' appelée tick extrait du flux d'entrée le mot suivant, cherche sa présence dans le dictionaire est place son token sur la pile de données. Le mot EXECUTE consomme ce token et l'exécute. Par exemple le code suivant:
42 ' DUP EXECUTE . . Place l'execution token du mot DUP sur la pile. EXECUTE ... l'execute. L'entier 42 est dupliqué. Il y a désormais deux fois le noimbre 42 qui seroont tour à tour affiché. Dans cet exemple particulier, on aurait simplement pu faire 42 DUP . . mais ces mots ont quand même leur utilité.
Il faut distinguer deux types de mots Forth:
- Les mots primitifs qui sont présents dans le coeur du langage et qui appellent le code
exécutable soit assembleur soit en C. Par exempl le mot DUP appelera l'assembleur i386
mov (%esp),%eax // duplicate top of stack push %eax - Les mots non primitifs définis par les mots Forth :
Le script suivant :
: SQR DUP * ;
: .SQR SQR . ;
va créer deux nouvelles entrées dans le dictionnaire comme indiqué dans la figure ci-dessous :
+--------------------+
| +---- | ------------------------------------------+-------------+
v v | | |
---------------- - - - ---------------- | ----------------------------------------- | ------------|------------
| 0x81 | DUP | | 0x83 | SQR | | DOCOL | DUP | * | EXIT | 0x84 | .SQR | | DOCOL | SQR | . | EXIT
---------------- - - - ------------------------|------|----|----|--------------------------|-------------------
^ | | | | |
| <-- - - - ------+ | | v v
+--------------------------------------------+----+
Regardons comment l'interpréteur exécute le script:
: FOO * * ;
Il execute le mot :, active l'interpréteur en mode compilation. Celui-ci va stocker en fin de dictionnaire les CFA des mots. : crée l'entête avec le mot suivant 0x83 FOO DOCOL ainsi que le pointeur du mot précédent. L'interpréteur lit le mot * et place son CFA en fin de dictionnaire. Idem pour le deucième *. Enfin il lit le mot ; qui doit être immédiatement exécuté, ce mot finalise la définition du mot (smudge bit, met a jout LAST) puis remet l'interpréteur en mode execution.
Les flèches représentent les adresses (LFA ou CFA) vers les mots existants du dictionnaire. Vu que BAR a été inséré dans le dictionnaire après FOO son LFA pointe vers FOO et le dictionnaire mémorise son LFA pour faire ses recherches sur les mots existants (la fameuse liste chainée).
Les littéraux 0x81, 0x83 (notation base 16) sont les tailles des mots avec le marqueur de séparation des entrées du dictionnaire. Les mots Forth DOCOL et EXIT sont des mots particuliers que l'on décrira plus tard. HERE pointe sur l'emplacement après EXIT du mot BAR.
Le dictionnaire possède deux informations supplémentaires qui sont eux-mêmes des mots Forth (donc aussi stockés dans le dictionnaire) :
- le LFA du dernier mot inséré dans le dictionnaire. C'est le mot Forth LAST (anciennement nommé LATEST) qui joue ce rôle;
- le premier emplacement libre du dictionnaire pour prochain mot est donné par le mot Forth HERE. HERE est mis à jour automatiquement après l'insertion d'une entrée ou d'un CFA. Il existe sur certain Forth un mot Forth appelé DP pour Dictionary Pointer, faisant partie des variables utilisateur, qui permet de changer l'emplacement indiqué par HERE (comme une tête de lecture/écriture).
A chaque fois qu'un mot est inséré à la définition d'un mot, c'est le mot HERE qui indique l'emplacement. Après l'ajout du mot, HERE est automatiquement déplacé pour toujours pointer sur un emplacement libre mais des mots comme ALLOC permettant de réserver de la mémoire déplace simplement HERE.
Deux avantages de cette structure de donnée sont :
- la non segmentation de la mémoire : déplacer un bloc d'entrée en mémoire est trivial (surtout si les adresses sont relatives et non absolues; on pensera à la concaténation de dictionnaires entre eux).;
- La recherche s'arrêtant au premier mot trouvé
- on peut donc écraser une ancienne définition comme il suit :
: FOO * * ;
: BAR FOO . ;
: FOO + + ;
: BAR FOO . ;
Interpréter BAR appellera deux additions.
L'inconvénient majeur de cette structure de donnée est que la recherche se fait avec une complexité linéaire que l'on note O(n). Pour palier à ce problèmes des mots Forth de même nature peuvent être regroupés en vocabulaires. Le vocabulaire est l'ancêtre des espaces de nommage des langages modernes (comme en C++ avec par exemple std::cout). Un vocabulaire est un mot Forth gérant un index de LAST mais pointant sur des mots choisis par le développeur. On a donc une sorte d'arbre où une recherche partirait d'un feuille (d'un vocabulaire spécifié, donc un mot équivalent à LAST) et se terminerait à la racine de l'arbre.
Moore avec son colorForth est passé à une table de hachage et pour sauver de la mémoire il compresse les noms des mots Forth avec un codage de Huffman.
Rappelons qu'un des flags dans l'entête d'une entrée indique si le mot est valide ou non (c'est le smudge bit). S'il est mis, alors il sera ignoré lors d'une recherche. Le mot FORGET suivit d'un mot existant (par exemple FORGET FOO) permet de tronquer toutes les définitions du dictionnaire jusqu'à ce mot. FORGET change simplement la valeur de LATEST. On prendra garde à ne pas supprimer tout le dictionnaire en tentant par exemple de supprimer le premier mot du dictionnaire.
Forth se prête bien à la récursivité : une récursivité terminale n'est rien d'autre qu'un saut en mémoire. Malheureusement, la syntaxe varie fortement d'un Forth à un autre. En effet, selon le Forth utilisé, lorsqu'une entête est créée dans le dictionnaire LATEST ne pointe pas encore dessus, d'autre Forth, le smudge bit est mis tant que le mot ; n'est pas exécuté effaçant le bit. Le mot SMUDGE doit être utilisé dans la définition pour commuter le flag en question.
Voici un exemple de récursivité :
: FACTORIELLE
DUP 1 >
IF
DUP 1 - FACTORIELLE *
THEN ;
Les premiers Forth l'implémentent comme une liste chaînée où tous les mots sont stockés les uns à la suite des autres (sans trous); certains Forth séparent les entrées des définitions (index séparé) tout en gardant le principe de liste chaînée entre les mots; d'autres utilisent une table de hachage, etc.
Différentes classes de mots
Je décris rapidement les différents catégories de mot sachant que
le lien Starting Forth ![]() les expliquera mieux :
les expliquera mieux :
- Gestion des piles
- gestion numérique
- arithmétique
- structure de contrôle
- action sur la mémoire
- gestion des entrées-sorties
- conversion
- mots de haut niveau
Commentaires : il existe deux types de commentaires en
Forth. Le premier type est le mot Forth immédiat ( qui
ignore tout caractère jusqu'au premier caractère )
rencontré. Par conséquent il est donc impossible d'imbriquer des
commentaires entre-eux. Et il ne faut pas oublier les espaces car
( est un mot Forth comme un autre. Ce type de commentaire est
préféré pour indiquer les paramètres d'un mot Forth. Pour plus de
renseignements sur la norme de la notation des paramètres
voir ce site ![]() .
.
: DIVISION ( n1 n2 -- n1/n2 ) / ;
Indique que DIVISION va consommer deux nombres signés où n1 est déposé dans la pile avant n2 (dans l'ordre de gauche à droite) et retourner le résultat dans la pile. Pour preuve 1 0 DIVISION doit retourner une exception tentative de division par zéro.
Le deuxième type de commentaire (ajouté tardivement) est le mot \ qui ignore la ligne entière. Il est utilisé pour de vrais commentaires autre que le renseignements de paramétres.
Gestion de la pile : permet de commuter l'ordre des données dans la pile. Par exemple DUP duplique le sommet, DROP le supprime, SWAP permute le sommet de la pile avec l'avant dernier, le mot . consomme et affiche le sommet de la pile, etc.
Mémoire : Le mot @ permet d'accéder au contenu d'une adresse. Le mot ! permet de stocker une valeur dans une adresse. Une variable en Forth est une mémoire nommée. Exemple :
15 VARIABLE TOTO
TOTO @ .
14 TOTO !
: ? @ . ;
TOTO ?
La première ligne créé une variable nommée TOTO avec la valeur 15. La deuxième ligne permet d'accéder au contenu de la variable puis l'affiche. La troisième ligne change la valeur de TOTO avec la valeur 14. La quatrième ligne crée un mot couramment utilisé. La dernière affichera la valeur 14.
Base : Forth permet d'afficher les nombres dans la base désirée. Exemple amusant :
: HEX 16 BASE ! ;
a .
HEX
BASE ?
a .
10 BASE !
BASE
a .
La première ligne redéfinit un mot courant du Forth permettant de passer en base 16 (hexadécimal). Par défaut Forth est en base 10 (décimale) donc la deuxième ligne doit générée une erreur (l'utilisateur voulait empiler le nombre a en base 16 (valant 10 en base 10) mais comme nous sommes en base 10 Forth détecte que ce mot lui est inconnu. Les lignes 3 à 5 permet de vérifier que nous sommes en base 16, la ligne 5 ne doit plus générer d'erreur. Ligne 7 à 9, l'utilisateur tente naïvement de repasser en base décimale mais cela échoue car le nombre 10 est interprète en base hexadécimale valant 16 en base décimale. Donc il n'y a pas eu de changement de base
Mots de structure : les classiques structures de contrôle connues des autres langages (comme le C) sont : le test conditionnel if-then-else, la boucle do-loop, la boiucle for, etc. Comme Forth utilise le système polonais inversé même le if-then-else du C devient IF ELSE THEN. Cela peut perturber le débutant mais on peut renommer THEN par FI ou ENDIF ce qui aidera les débutants.
: ENDIF [COMPILE] THEN ; IMMEDIATE
De plus IF ELSE THEN doivent obligatoirement être utilisés dans une
définition sinon le compilateur échouera. En mode interprétation if
faudra utiliser les mots IF ELSE THEN qui équivaut au #if #else
#endif du langage C. Le lien
suivant ![]() explique en quoi Moore a encore réduit le nombre de mots de
structure. Par exemple le ELSE n'existe plus. Avant :
explique en quoi Moore a encore réduit le nombre de mots de
structure. Par exemple le ELSE n'existe plus. Avant :
: MOT TEST IF ACTION1 ELSE ACTION2 THEN ACTION3 ;
Devient :
: SOUS-MOT TEST IF ACTION1 EXIT THEN ACTION2 ;
: MOT SOUS-MOT ACTION3 ;
Arithmétique : addition, conversion entier signé et non
signé, opération booléenne. Point important : contrairement à des
langage tel que C où le faux vaut 0 et le vrai vaut toutes valeurs
différentes de 0 (mais où 1 est en général retourné), en forth le faux
vaut -1. Le lien ![]() en
parle plus longuement. Sinon, voici un exemple :
en
parle plus longuement. Sinon, voici un exemple :
1 0 <> . La pile de données des Forth permet uniquement de manipuler des entiers (signés et non signés) ou des adresses de la machine virtuelle (qui sont finalement vues comme un entier), les valeurs en floatants (float et double du langage C) ne sont pas gérées nativement, une bibliothèque devant alors être chargée pour les gérer.
En fait, par défaut, Forth n'utilise pas une seule pile mais deux piles. La deuxième, appelée pile de retour, sert à l'interpréteur Forth pour mémoriser l'ordre d'exécution des mots appelant d'autres mots. Cette pile est automatiquement manipulée par lui mais laisse, quand même, à l'utilisateur la possibilité de déplacer et stocker temporairement des éléments de la pile de données (ce qui n'est pas toujours sans risque). Nous y reviendrons plus tard.
Des Forth modernes peuvent ajouter nativement des piles de données supplémentaires comme une pile d'entiers (appelés pile alternative) et/ou une pile des floatants. En général, la pile de donnée supplémentaire permet d'éviter l'utilisation de la pile de retour comme stockage temporaire et rendant l'interpréteur Forth plus fiable aux erreurs de programmation.
Un système de sécurité permet de vérifier que les piles ne débordent pas (par le haut ou par le bas) et prévient l'utilisateur en arrêtant l'exécution du mot en cours. Charles H. Moore quand à lui préfère utiliser un tampon circulaire par rapport à une pile. Il n'y a plus de risque possible de débordement de mémoire mais il n'a pas ajouté de système pour prévenir l'utilisateur car selon lui le développeur doit maîtriser le nombre d'opérandes qu'il manipule. De plus, ce système permet de décider à tout instant la pile comme étant vide.
On constatera après l'exécution du dernier exemple, que la profondeur de pile des donnée n'a pas été changée. Ceci n'est pas une contrainte mais le standard Forth impose de laisser intact la profondeur des piles pour au moins deux cas :
- lors des définitions d'un nouveau mot Forth
- et la fin d'un fichier quand il est inclus par un autre fichier.
Fonctionnement de interpréteur externe
Un interpréteur Forth fonctionne très simplement : tant que le flux d'entrée n'est pas fini, les mots sont lus les uns après les autres. L'interpréteur possède deux modes : soit il est mode exécution, soit il est en mode compilation.
En mode EXECUTION :
- Si le mot lu est connu du dictionnaire alors il est alors exécuté;
- sinon l'analyseur (parser) vérifie que le mot lu n'est pas un nombre (dans la base actuelle) : si c'est le cas alors un nombre est alors déposé dans la pile de données;
- sinon le mot n'est pas connu et n'est pas un nombre : une erreur prévient l'utilisateur et arrête le processus.
En mode COMPILATION les mots non-immédiats qui sont lus, s'ils sont connus du dictionnaire, leurs CFA sont ajoutés les uns à la suite des autres au dans la définition courante du dictionnaire. Si un mot n'est pas connu une erreur prévient l'utilisateur et arrête le processus.
Du peu de mots Forth que l'on a vus, c'est le mot : qui force le mode COMPILATION de l'interpréteur alors que le mot ; le fait passer en mode EXECUTION. On peut déjà se poser la question comment l'inter peut passer en mode exécution avec le mot ; s'il ne fait que compiler tous les mots qu'il voit; logiquement, il ne devrait jamais s'arrêter de compiler. La réponse vient du champ FLAGS où l'un des bits permet de rendre un mot Forth immédiat. Par immédiat on sous-entend que le mot sera immédiatement exécuté même si l'interpréteur est en mode compilation. Attention: un mot immédiat ne commute pas le mode de l'interpréteur : il est simplement interprété !
On raffine donc le définition et l'on profite pour ajouter un cas particulier :
En mode COMPILATION :
- les mots non immédiats lus, s'ils sont connus du dictionnaire, sont ajoutés les uns à la suite des autres au dictionnaire dans la définition courante;
- Si le mot est immédiat et connu du dictionnaire il est alors interprété;
- si le mot n'est pas connu il est testé pour savoir si c'est un nombre : si oui
- il est ajouté à la définition mais on intercalera avant le mot LITERAL pour ne pas l'interpréter comme un mot Forth; sinon le mot n'est pas connu une erreur prévient l'utilisateur et arrête le processus.
Si l'inter lit tous les mots les uns après les autres, avec le code
: FOO * * ;
FOO n'étant pas défini, l'interpréteur devrait déclencher une erreur. En fait non, car comme on l'a dit l'interpréteur sait lire le mot suivant et le mot : quand il est exécuté va lire le mot suivant, à savoir FOO afin de créer une nouvelle entrée dans le dictionnaire. Par conséquent le mot suivant que l'interpréteur va lire sera *.
L'interpréteur Forth à deux modes (états) soit il est en mode interprétation soit en mode compilation. Des mots comme : et ; permettent respectivement de passer en mode compilation puis interprétation.
- En mode interprétation, la définition des mots lus sont recherchés dans le dictionnaire puis exécutés.
- En mode compilation, une entête dans le dictionnaire est créée afin de permettre de retrouver le nouveau mot, puis chaque mot lus, s'ils ne sont pas considérés comme immédiats, sont recherchés dans le dictionnaire et leur référence stockée dans la définition du mot en cours de définition.
Le mot IMMEDIAT rend immédiat le dernier mot du dictionnaire. Pour rappel un mot immédiat n'est pas compilable mais directement interprété quand l'interpréteur est en mode compilation. Voici un exemple plus évolué de mot immédiat : on se propose d'ajouter un système de commentaires à Forth. Pour cela on suppose que le mot TYPE existe déjà (ce qui en général le cas) ce mot permet d'ignorer les caractères du tampon d'entrée jusqu'au caractère indiqué comme paramère.
: ( ')' TYPE ;
IMMEDIATE Dés que le 'analyseur exécutera le mot ( il ignorera tous les mots jusqu'à trouver le mot ) et comme il est immédiat il va fonctionner dans une définition (quand l'interpréteur sera en mode compilation). Notons qu'il existe un autre type de commentaire Forth le mot \ ignore entièrement la ligne courante.
Si l'on désire rendre immédiat un certains nombre de mots de façon temporaire dans une définition il faut les délimiter par les mots [ et #]. Ces mots modifient l'état de l'interpréteur: interprétation ou compilation mais ne changent pas le smudge bit des mots.
Si l'on désire compiler un mot immédiat il faut placer avant le mot [COMPILE#] (qui lui aussi est immédiat). Le mot COMPILE joue le même rôle que [COMPILE#] mais est non immédiat. Il permet de ... TODO A FINIR ... Notons que ces mots sont désuets à cause du risque de confusion pour les développeurs pour se souvenir de qui est immédiat, par conséquent on utilisera plutôt le mot POSTPONE qui appelle l'un ou l'autre automatiquement selon le caractère immédiat du mot qui lui succéde.
On se propose de créer deux nouveaux Forth : DO et LOOP qui permettent de faire une boucle. On supposera l'existence d'un mot Forth (non officiel) 0BRANCH qui fait un saut relatif à la condition que le sommet de la pile vaut 0.
: DO
COMPILE SWAP
COMPILE >R
COMPILE >R
HERE
; IMMEDIATE
: LOOP
COMPILE R>
COMPILE 1+
COMPILE R>
COMPILE 2DUP
COMPILE >R
COMPILE >R
COMPILE <
COMPILE 0=
COMPILE 0BRANCH
HERE - ,
COMPILE R>
COMPILE R>
COMPILE 2DROP
; IMMEDIATE
Voici un exemple typique de ces mots qui affiche ...
: DECADE 10 0 DO 1 . LOOP ;
Fonctionnement de interpréteur interne
Variables et constante
Nous avons vu que Forth permet de stocker des mots Forth mais il peut également servir à stocker de la mémoire. En effet on a dit dans une section précédente que la variable DP permet de changer où HERE indique le premier emplacement libre. Par conséquent on peut se réserver des emplacements mémoires et l'idéal est de donner un nom aux emplacemets.
Le mot ALLOC permet de déplacer DP du nombre d'octet voulu (un ALLOC pour 1 cellule est le mot ,)
Un langage evolutif
Article précédent: |
Page d'accueil |
Aller en haut |
Article suivant: |
| Principe moindre action | Boîte à outils Max+ |